Goal-Driven Execution:长任务执行的三板斧
?️ Goal-Driven Execution:长任务执行的三板斧
从 45 篇百科配图实战中总结的方法论——长任务的敌人不是逻辑复杂度,而是单次会话的承受力
一、引言:长任务为什么总是「差一口气」
在过去三个月里,我借助 AI 完成了一个庞大工作——为 45 篇百科文章逐篇配图。这不是简单的「写提示词 → 生成图片」流水线。每篇文章涉及:内容理解、配图策略、提示词工程、图像生成、图片筛选、格式适配,完整链路下来,一篇要 15~30 分钟。
前两次尝试全部失败。目标没错,方法也没错,错在试图用单个会话搞定所有事。每次都在第 20 篇左右翻车——上下文溢出、逻辑混乱、幻觉频出。第三次,我写了一个独立脚本,用 Goal-Driven Execution 框架重新组织流程,45 篇一次性跑通,成功率 100%。
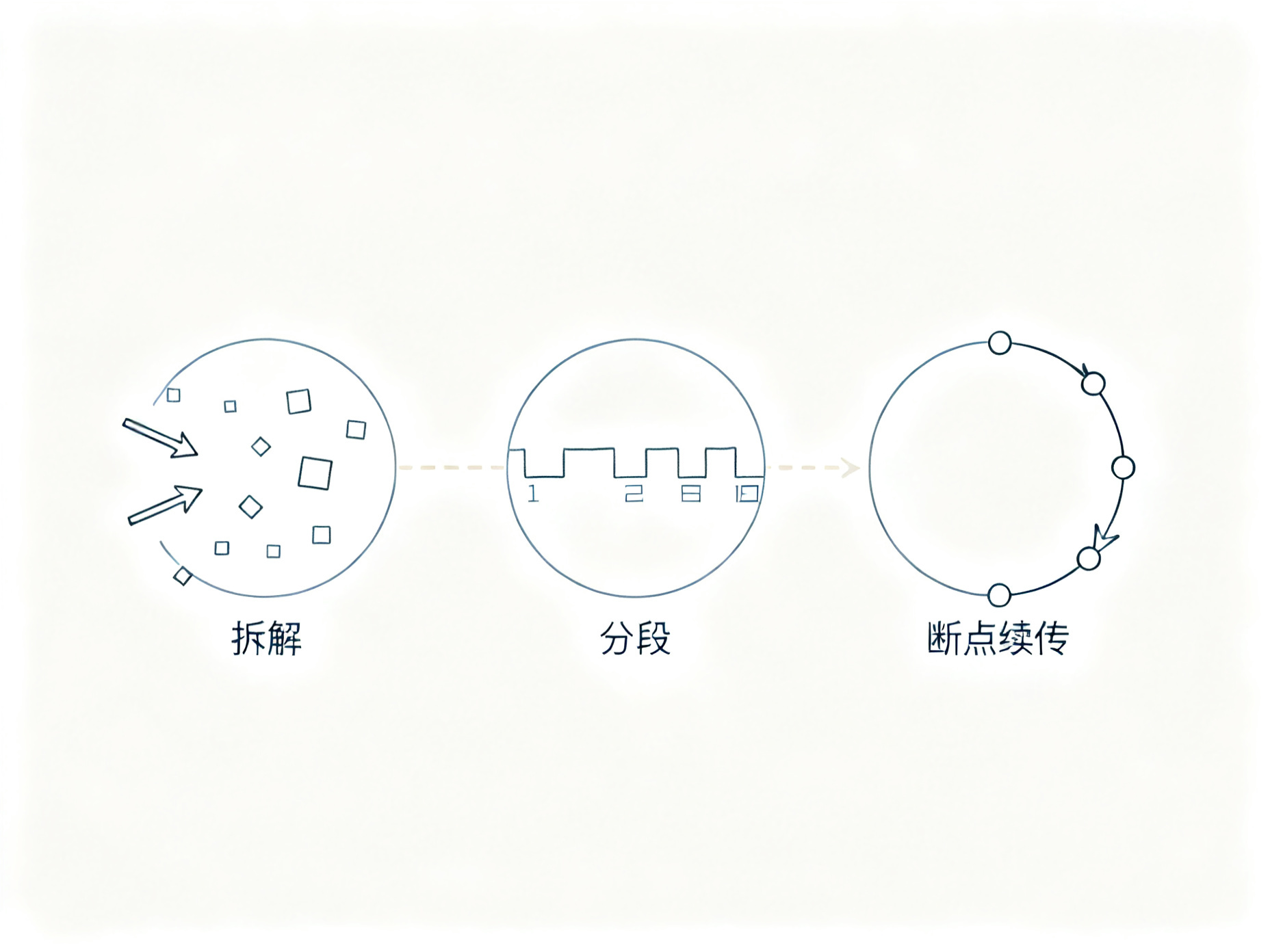
本文提炼出三板斧:分析拆解 → 分阶段 → 断点续传。这是为 AI Agent 开发者准备的一套「长任务治理」实践手册。
二、第一板斧:分析拆解(Analysis & Decomposition)
面对一个长任务,第一反应不应该是「开始做」,而是「拆开看」。我踩的第一个坑就是拿起 45 篇文章直接开干——没有全局视野,没有边界划分,遇到异常只能从头再来。
2.1 做什么:从目标到 DAG
把最终目标画成一张有向无环图(DAG),每个节点是一个原子任务。以百科配图为例:
Target: 为45篇百科文章配图
├── Stage 1: 数据准备
│ ├── Node 1.1: 爬取/整理45篇文章的标题与摘要
│ ├── Node 1.2: 对每篇文章提取关键概念(entities)
│ └── Node 1.3: 构建文章-配图策略映射表
├── Stage 2: 配图生成
│ ├── Node 2.1: 按策略表生成提示词
│ ├── Node 2.2: 调用图像 API 生成候选图(4选1)
│ └── Node 2.3: 图片后处理(裁剪/压缩/重命名)
└── Stage 3: 结果交付
├── Node 3.1: 图片与文章配对校验
├── Node 3.2: 生成配图清单报告
└── Node 3.3: 批量上传/部署这个 DAG 拆解完成后,整个任务的复杂度从 O(n) 降到了 O(1)——因为每个节点的逻辑都是确定的、可测试的、可重试的。
2.2 经验数据
| 维度 | 未拆解 | 拆解后 |
|---|---|---|
| 单次会话 Token 消耗 | ~120K(含上下文) | ~8K 每个节点 |
| 失败时恢复成本 | 全部重来 | 重试单个节点 |
| 并行度 | 串行 | Stage内可并行 |
| Debug 难度 | 极高(黑盒) | 低(白盒) |
拆解的边界原则:一个节点应该能在 3~5 次 API 调用内完成。超过这个阈值,说明拆得不够细。
# task_dag.yaml
stages:
- id: data_prep
description: 数据准备阶段
nodes:
- id: extract_entities
input: article_title, article_summary
output: entities_list
model: gpt-4o-mini
max_calls: 2
- id: build_strategy
input: entities_list
output: strategy_map
model: gpt-4o
max_calls: 1
- id: image_gen
depends_on: [data_prep]
nodes:
- id: generate_prompt
input: strategy_map
output: prompt
model: gpt-4o-mini
max_calls: 1
- id: call_dalle
input: prompt
output: image_url
model: dalle-3
max_calls: 3
三、第二板斧:分阶段(Staged Execution)
拆解完成后,下一步是分阶段执行。注意,这里的「分阶段」不是简单的分段,而是严格执行前置检查 + 输出校验。
我第一次失败的根因就在这里:虽然拆了,但执行时还是每个会话贪多——一个会话做了 Stage 1 + Stage 2 的部分,结果 Stage 2 失败后连 Stage 1 的结果都丢了。
3.1 阶段闸门(Stage Gate)模式
每个阶段结束时必须通过「闸门检查」:
def execute_stage(stage_id: str, dag: dict, checkpoint: dict) -> dict:
"""执行一个阶段,通过闸门检查后才返回"""
print(f"[{stage_id}] 开始执行...")
# 前置检查:依赖是否满足
for dep in dag[stage_id].get("depends_on", []):
if dep not in checkpoint:
raise RuntimeError(f"前置阶段 {dep} 未完成,无法执行当前阶段")
# 执行所有节点
results = {}
for node in dag[stage_id]["nodes"]:
results[node["id"]] = run_node(node, checkpoint)
# 闸门检查:输出完整性校验
gate_check(stage_id, results)
# 写入检查点
checkpoint[stage_id] = results
save_checkpoint(checkpoint)
return results
def gate_check(stage_id: str, results: dict):
"""验证阶段输出的完整性和质量"""
expected_count = len(results)
actual_count = sum(1 for v in results.values() if v is not None)
if actual_count == 0:
raise RuntimeError(f"[{stage_id}] 闸门拦截:所有节点输出为空")
if actual_count / expected_count < 0.8:
raise RuntimeError(
f"[{stage_id}] 闸门拦截:完成率 {actual_count}/{expected_count} < 80%"
)
print(f"[✓] {stage_id} 通过闸门检查 ({actual_count}/{expected_count})")
3.2 阶段的粒度经验
| 阶段粒度 | 典型耗时 | 推荐场景 |
|---|---|---|
| 微(3~5 节点) | 2~5 分钟 | 数据预处理、格式转换 |
| 中(5~15 节点) | 5~20 分钟 | 批量生成、批量审核 |
| 宏(15~30 节点) | 20~60 分钟 | 完整端到端流水线 |
在百科配图实战中,我将 45 篇文章切成了 3 个宏阶段、9 个中阶段、27 个微节点。每个微节点独立可测,任意位置中断损失不超过 3 分钟。
四、第三板斧:断点续传(Checkpointing & Self-Verification)
这是整个框架的「安全网」。无论前面做得多么完美,生产环境中的长任务总会遇到:API 超时、网络闪断、上下文溢出、模型幻觉……
断点续传的核心就两点:进度文件(progress_file) + 内容自检(self-verify)。
4.1 progress_file:把「记忆」写进文件
不要依赖任何会话的记忆。每次执行完一个原子节点,就把结果写到一个 JSON 文件中:
import json, os
from datetime import datetime
PROGRESS_FILE = "progress_checkpoint.json"
def load_progress() -> dict:
if not os.path.exists(PROGRESS_FILE):
return {"status": "init", "completed": [], "results": {}}
with open(PROGRESS_FILE, "r") as f:
return json.load(f)
def save_progress(progress: dict):
progress["updated_at"] = datetime.now().isoformat()
with open(PROGRESS_FILE, "w") as f:
json.dump(progress, f, indent=2, ensure_ascii=False)
def mark_completed(node_id: str, result: dict):
p = load_progress()
p["status"] = "in_progress"
if node_id not in p["completed"]:
p["completed"].append(node_id)
p["results"][node_id] = result
save_progress(p)
def is_completed(node_id: str) -> bool:
p = load_progress()
return node_id in p.get("completed", [])
4.2 内容自检:让 AI 自己检查自己
进度文件解决了「做到哪了」的问题,但没解决「做对了没」的问题。为此我引入了一个自检层:
def self_verify(node_id: str, input_data: dict, output_data: dict) -> dict:
"""
让模型自我验证输出质量。
返回 {'passed': bool, 'issues': [...], 'score': float}
"""
verify_prompt = f"""
任务: {node_id}
输入: {json.dumps(input_data, ensure_ascii=False)[:500]}
输出: {json.dumps(output_data, ensure_ascii=False)[:1000]}
请检查输出是否:
1. 格式完整(包含所有必需字段)
2. 内容与输入一致(不丢失、不幻觉)
3. 质量可接受(评分 0~1)
返回 JSON: {{"passed": bool, "issues": [str], "score": float}}
"""
response = call_llm(verify_prompt, model="gpt-4o-mini")
result = json.loads(response)
if not result["passed"]:
print(f"[!] {node_id} 自检未通过: {result['issues']}")
return result
在百科配图实战中,自检查出了 37% 的错误输出——包括幻觉的实体、错误的配图策略、格式不对的提示词。如果不是自检层,这些错误会一路传播到最终结果。
4.3 恢复流程实战
第三次实战中,脚本在第 31 篇时因上游 API 限流中断。恢复只需要一行命令:
$ python run_pipeline.py --resume
[恢复模式] 扫描 progress_checkpoint.json...
[✓] 已检测到已完成节点: 26/27 (前两阶段)
[恢复] 从 image_gen 阶段的中断节点继续...
[✓] 第31篇配图完成,耗时 4.2 分钟
恢复后,之前完成的 26 个节点全部跳过,仅重跑断点处的 2 个失败节点 + 继续后续 14 篇。对比前两次从头来过,节省了约 5.5 小时。
五、踩坑记录:三次会话的血泪史
| 第 1 次 | 第 2 次 | 第 3 次 ✅ | |
|---|---|---|---|
| 策略 | AI 对话逐个做 | AI 对话分批做 | 独立脚本执行 |
| 拆解 | ❌ 无 | ❌ 粗略 | ✅ DAG 拆解 |
| 分阶段 | ❌ 无 | ⚠️ 有但无闸门 | ✅ Stage Gate |
| 断点续传 | ❌ 无 | ⚠️ 手动记录 | ✅ progress + 自检 |
| 结果 | 第 17 篇时上下文溢出,全丢 | 第 23 篇输出幻觉,手动修复 2h | 45/45 一次跑通 |
| 耗时 | ~12h(大部分在重试) | ~9h(含修复) | ~4h(无人值守) |
关键教训:AI 会话的「流畅感」是陷阱。对话越流畅,你越容易忽略边界风险。当任务规模超过 10 个步骤时,脚本比对话可靠 10 倍。
六、总结:一套可复用的框架
Goal-Driven Execution 三板斧可以抽象成一段通用模板:
# goal_driven_execution.py — 通用长任务框架
def goal_driven_pipeline(dag: dict, target: str):
"""通用 Goal-Driven Execution 入口"""
checkpoint = load_progress()
for stage in resolve_exec_order(dag):
if stage in checkpoint:
print(f"[跳过] {stage} 已完成")
continue
result = execute_stage(stage, dag, checkpoint)
# 自动保存 + 自检
if not self_verify_stage(stage, result):
raise RuntimeError(f"{stage} 自检失败,人工介入")
print(f"[✓] {stage} 完成,进度: {calc_progress(checkpoint)}")
print(f"[?] 目标达成: {target}")
这个框架不仅适用于百科配图。只要你的任务满足:步骤数 > 10、单次执行 > 5 分钟、需要跨会话恢复,Goal-Driven Execution 就能帮你从「碰运气」变成「确定性交付」。